
In my previous blog article I showed how you can use the excellent OpenCV and dlib libraries to easily create a program that can detect a face and track it when the face is moving.
The code in the previous blog article was created in such a way that if it was not tracking any face, it would look for all faces in the current frame. If multiple faces were found, the largest face was selected and used for tracking. As long as the dlib correlation tracker was able to successfully track the face, no other faces would be detected.
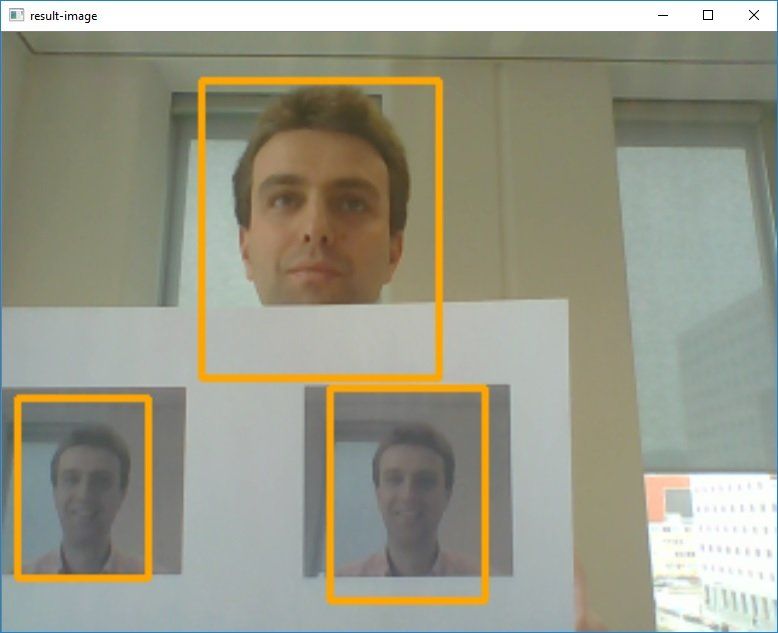
In this post, I will show the modifications that are needed to go from tracking the largest face to tracking all faces that are visible. So, if there are three faces on the screen we would like to see that each of the three faces is detected:
The biggest change will be that even if we are tracking one or more faces, we will have to run the HAAR face detection every so many frames to detect any new face that might have become visible in the meantime. When tracking just one face, we don't have to worry about this: only after the tracker lost track of the face, we have to start looking for a new face to track.
An import problem we need to solve for this is that when we run the face detection, we somehow need to determine which of the detected faces match the faces we are already tracking with the correlation trackers. One simple approach for checking if a detected face matches an existing correlation tracker region is to see whether the center point of the detected face is within the region of a tracker AND if the center point of that same tracker is also within the bound of the detected face.
So the approach to detect and track multiple faces is to use the following steps within our main loop:
- Update all correlation trackers and remove all trackers that are not considered reliable anymore (e.g. too much movement)
- Every 10 frames, perform the following:
- Use face detection on the current frame and find all faces
- For each found face, check if there exists a tracker for which holds that the center point of the detected face is within the region of the tracker AND whether the center point of that same tracker is within the bounding box of the detected face.
- If there exist such a tracker, the detected face most likely was already being tracked. If no such tracker exists, we are dealing with a new face and we have to start a new tracker for this face.
- Use the region information for all trackers (including the trackers for the new faces created in the previous step) to draw the bounding rectangles
Within the main loop, we can update all existing trackers and delete all of the trackers for which the tracking quality falls below the threshold we have set (in the code below the value 7). The lower you set this value, the less the tracker will loose the object, but the higher the chances are you are not tracking the original object anymore.
#Update all the trackers and remove the ones for which the update
#indicated the quality was not good enough
fidsToDelete = []
for fid in faceTrackers.keys():
trackingQuality = faceTrackers[ fid ].update( baseImage )
#If the tracking quality is good enough, we must delete
#this tracker
if trackingQuality < 7:
fidsToDelete.append( fid )
for fid in fidsToDelete:
print("Removing tracker " + str(fid) + " from list of trackers")
faceTrackers.pop( fid , None )
Every 10 frames, we now want to detect all the faces in the current frame and map each of the found faces to an existing tracked face where possible or create a new tracker for faces we were not yet tracking.
#Now use the haar cascade detector to find all faces
#in the image
faces = faceCascade.detectMultiScale(gray, 1.3, 5)
#Loop over all faces and check if the area for this
#face is the largest so far
#We need to convert it to int here because of the
#requirement of the dlib tracker. If we omit the cast to
#int here, you will get cast errors since the detector
#returns numpy.int32 and the tracker requires an int
for (_x,_y,_w,_h) in faces:
x = int(_x)
y = int(_y)
w = int(_w)
h = int(_h)
#calculate the centerpoint
x_bar = x + 0.5 * w
y_bar = y + 0.5 * h
#Variable holding information which faceid we
#matched with
matchedFid = None
#Now loop over all the trackers and check if the
#centerpoint of the face is within the box of a
#tracker
for fid in faceTrackers.keys():
tracked_position = faceTrackers[fid].get_position()
t_x = int(tracked_position.left())
t_y = int(tracked_position.top())
t_w = int(tracked_position.width())
t_h = int(tracked_position.height())
#calculate the centerpoint
t_x_bar = t_x + 0.5 * t_w
t_y_bar = t_y + 0.5 * t_h
#check if the centerpoint of the face is within the
#rectangleof a tracker region. Also, the centerpoint
#of the tracker region must be within the region
#detected as a face. If both of these conditions hold
#we have a match
if ( ( t_x <= x_bar <= (t_x + t_w)) and
( t_y <= y_bar <= (t_y + t_h)) and
( x <= t_x_bar <= (x + w )) and
( y <= t_y_bar <= (y + h ))):
matchedFid = fid
#If no matched fid, then we have to create a new tracker
if matchedFid is None:
print("Creating new tracker " + str(currentFaceID))
#Create and store the tracker
tracker = dlib.correlation_tracker()
tracker.start_track(baseImage,
dlib.rectangle( x-10,
y-20,
x+w+10,
y+h+20))
faceTrackers[ currentFaceID ] = tracker
#Increase the currentFaceID counter
currentFaceID += 1
In order to show that each face is recognized and tracked separately, we also want to write a descriptive text above the bounding rectangle. To make this functionality show a glimpse of what we want to achieve (full face recognition) we first show a text indicating we are in a detection face, and after that we show the actual description. After a face has been detected, we will use a small background thread that will set the description for region after about 2 seconds. Now the display can be achieved by checking whether there already exists a description for this tracker and write the text accordingly:
#Now loop over all the trackers we have and draw the rectangle
#around the detected faces. If we 'know' the name for this person
#(i.e. the recognition thread is finished), we print the name
#of the person, otherwise the message indicating we are detecting
#the name of the person
for fid in faceTrackers.keys():
tracked_position = faceTrackers[fid].get_position()
t_x = int(tracked_position.left())
t_y = int(tracked_position.top())
t_w = int(tracked_position.width())
t_h = int(tracked_position.height())
cv2.rectangle(resultImage, (t_x, t_y),
(t_x + t_w , t_y + t_h),
rectangleColor ,2)
#If we do have a name for this faceID already, we print the name
if fid in faceNames.keys():
cv2.putText(resultImage, faceNames[fid] ,
(int(t_x + t_w/2), int(t_y)),
cv2.FONT_HERSHEY_SIMPLEX,
0.5, (255, 255, 255), 2)
else:
cv2.putText(resultImage, "Detecting..." ,
(int(t_x + t_w/2), int(t_y)),
cv2.FONT_HERSHEY_SIMPLEX,
0.5, (255, 255, 255), 2)
When we combine all of this, we now can do detection of multiple faces and track these faces separately. As soon as we have detected a face and we are tracking it, we only would have to do face recognition once because as long as we are tracking a face we know the link between the tracked region and the properties.
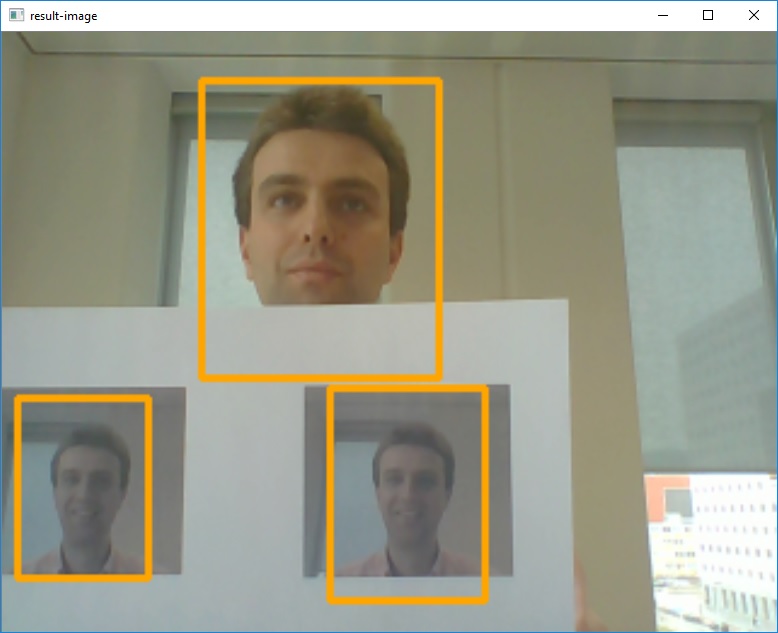
A demo of this new version is given in the animation below:

Like the previous article, you can find the complete source of this project on my Github page.