

Recently, started to play around with DVC and although the main idea is very cool and quite clear (and the tutorials were also quite clear), one of the things I did not see that much is how to deal with multiple different model types over time.
For example, in case you start out with a very simple logistic regression model and later on you decide to investigate more complex models like random forest or xgboost models.
So if you are working with just one type of model, one way I can see this with DVC is the following:
- Create your project
- Initialize DVC on your project
- Implement logistic regression in a python script
- Add a new stage train_model to your dvc.yaml that depends on for example the train.pkl output of a train_test_split stage and outputs a model.pkl file with the trained model parameters
- Add a new stage evaluate_model to your dvc.yaml that depends on the model.pkl file of the train_model stage and the test.pkl output of a train_test_split stage
Step 5 could then also write some metrics to a test.json file such that you can keep track of the performance.
If you make small changes to the model (e.g. changing the feature-set or some hyper parameters in case your doing things with Ridge for example), I would consider this just small variations on one existing model-type. But it becomes different when you now start looking at a new type of model that you would like to compare to your first logistic regression model, for example you want to investigate an xgboost model. At the moment, I see two separate ways of dealing with this: always just one active model or multiple models
Always one active model
One way is to create just a new branch in your code, replace the code that is being called by the scripts executed in the DVC stages and keep all other things the same. This means that instead of the logistic regression, your train_model and evaluate_model stage now will refer to your new xgboost model. Then if you are happy with the performance compared to the previous model, you just merge your branch back into master and this way replace the original logistic regression model with your new xgboost model.
This also means that you will use the same metrics file, now with the metrics for the new model
A big advantage of this approach is that you can easily keep track of the performance of any evolution of your solution for the problem (i.e. could be different model types, different features, different hyper parameters, etc). If each version of your solution always writes to the same test.json metrics file, you can easily see how you were improving over time.
A disadvantage is that you must determine based on for example git tags when you changed model types for example
Multiple simultaneous models
Another approach would be to just create two new stages for each type of model you want to investigate. For example, if you want to add the xgboost model, you would add train_xgboost_model and evaluate_xgboost_model stages to your dvc.yaml file. Also, the original two stages might then also be called train_logistic_regression and evaluate_logistic_regression.
If you look at the DAG that would be created, that would then be something like the DAG below:
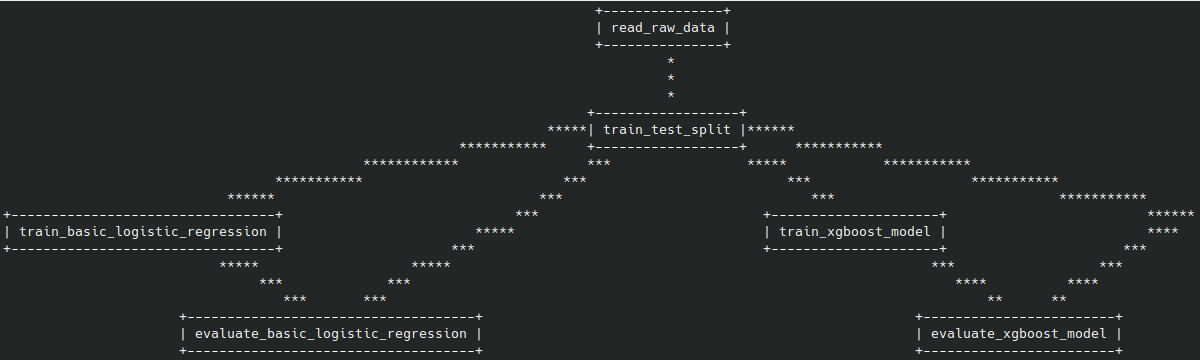
The drawback of this approach is that you will always have to keep track of which model you consider to be the active one in each of the tags if you want to track your improvements over time. A big advantage is that whenever you have a new dataset you want to train your data on, you can easily compare all of the different model types at the same time.
Hybrid approach
Maybe one approach that combines the best of both would be to have two stages for each of the different model types you would like to consider (train and evaluate) and create two separate stages for the model that you consider to be the selected one: train_selected_model and evaluate_selected_model.
These two additional stages would then be a copy of the stages for the model you consider active. This means that if you start out with a logistic regression model, the train_selected_model and evaluate_selected_model would be copies of the train_logistic_regression and evaluate_logistic_regression.
If later on you find that an xgboost model is outperforming the logistic regression significantly, you can then update the train_selected_model and evaluate_selected_model stages to refer to the train and evaluate stages of the xgboost model.
This approach would allow you to easily keep track of the main performance of your selected model (the type of which could change over time) as well as having access to the performance of all other approaches also
Other approaches/solutions?
Since I only started investigating DVC very recently, still in the process of learning all of the capabilities and what it can do. So far, very impressed with DVC though and really think it is a very good way to make sure that you can easily reproduce any model in the future. Also played a bit with the experiments feature that recently got released and have to say that I really like it also!
Very curious to hear your opinion about DVC. Also, very interested in hearing opinions about dealing with different model types for the same problem within one project. How do you solve this? Let me know in a comment!