
For some of the things I am currently working on, I am using a Spark cluster. However, direct access is not possible and the only two ways that I can run spark jobs on the cluster are using Zeppelin notebooks and using the Livy REST API, both installed on an edge node (where Zeppelin is actually using Livy also). So the layout is similar to the one depicted below:
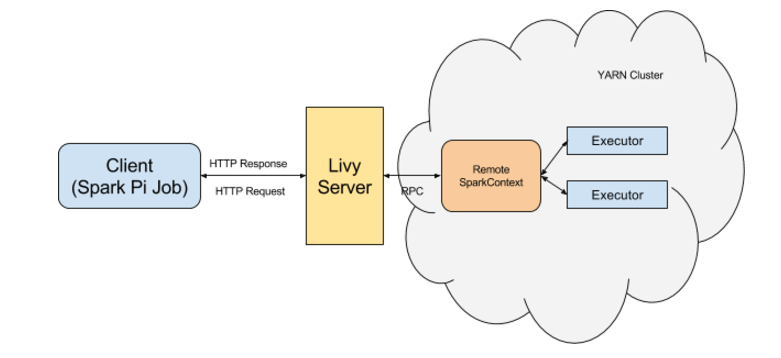
Although I really do like notebooks (mostly Jupyter for normal python stuff, but also for some exploratory pyspark stuff I do appreciate Zeppelin ), the major problem I have with them is the fact it is difficult, if not nearly impossible to have a good Git work flow with them. So for anything that is not exploratory, I typically want to work with just Python scripts that I can put easily into a Git repository. This way, I can keep track of all modifications that I make.
Since I do have access to the Livy REST API, which itself is essentially a wrapper around spark-submit, I decided that we needed to go deeper and add another wrapper layer around Livy again :) 
The result of this is the python script livy_submit, which allows you to easily submit some pyspark code to the cluster for execution. The default is to create a new Livy session for each job that you send, but optionally, you can also connect to an existing Livy session.
Each python script you submit with livy_submit is executed as a separate statement within the Livy session, which means that if you choose to reconnect to an existing livy session, the new script you send is just added as a new statement. This also means that all the variables created in the earlier statements will all exist also.
Basic livy_submit usage
Suppose you have the extremely basic calculate_pi.py script to calculate approximation of pi using spark. The contents of this script are the following:
import sys
from random import random
from operator import add
# Change this to play around with larger sets
partitions = 2
n = 10000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
Now to submit this script to your spark cluster using livy_submit, you can use the following code:
livy_submit https://edgenode:port/path_for_livy -s calculate_pi.py
The above code will execute the following steps:
- Connect to the Livy server given by the URL
- Create a new Livy session and display the session ID
- Poll the Livy server to check whether the new session is available (in idle state)
- Create a new statement using the contents of the file
calculate_pi.pyand execute this statement - Poll the Livy server for the status of the job and display this as progress bar
- After the statement is finished, retrieve the output (everything printed to stdout) from the driver and display this to the user
- Delete the Livy session
The output of the code will be something like:
(test_env) C:\Users\Guido>livy_submit https://edgenode:port/path_for_livy -s calculate_pi.py
Started session with id = 1028
Waiting for session to become idle before sending statements DONE
Now executing the contents of the script LivySubmit - calculate_pi.py (statement id=0)
available |##################################################| 100.0% Complete
Output of the application on the driver:
--------------- text/plain ---------------
Pi is roughly 3.137200
Finished executing script, now removing the spark session
{'msg': 'deleted'}
(test_env) C:\Users\Guido>
Source and Installation
The source for livy_submit can be found on GitHub. I have also uploaded the project to PyPI.org, which means that you can install it with the following statement:
pip install Livy-Submit
Next steps
Livy-Submit can already do more than just the statement provided above. For example, you can also set different spark settings like the number of executors to use, the amount of memory per executor, the number of cores per executor, etc.
Additionally, you can also set some default values for the LivySubmit URL using environment variables.
I will provide some more details and examples about these features in future blog posts. Also, the application is still under development. If you have any ideas or run into any problems with it, please drop me a comment or fill in an issue on the GitHub page.